In a recent blog post, Brandon Mahoney asked How Big Can CMS Infrastructure Get? with the short answer being as much as you want to spend. It is true today as it always has been, that you can build any infrastructure to fulfill any set of requirements and requirements such as disaster recovery and performance traditionally can drive you to provision infrastructure that will for the most part remain idle in a data centre. Take a cloud based approach and you can change your overall footprint of infrastructure which will save costs and improve agility.
So how can you avoid over spending on infrastructure but achieve your requirements?
In a standard SDL Web infrastructure, like Brandon shares, there are various strategies you can employ to reduce the overall spend when you use public cloud. If you compare an always-on on-premises environment to an always-on cloud environment, then it could be that the difference in costs is not dramatically different – although it should be noted that businesses rarely have a good grip on what things actually cost (see AWS’ TCO calculator for some help with that). If you are not using higher-level services, like Kinesis, that are fully managed by AWS so you will still need to do some or all of the hard work in managing the environment yourself. Automation can often be applied to both something in the cloud and something on-premises (but rarely is) so that means you are ultimately you are still managing infrastructure and therefore to reduce the cost of it is to manage less of it, more efficiently without compromising performance and reliability. Five principles to this strategy are:
- Automate everything – if you do something more than three times, write a script or process for it.
- Build stateless applications – this way you can easier send servers to their deaths if their existence has ceased to have value
- Scale servers elastically – easier if they are stateless but add and reduce load as needed based upon demand. Demand in the form of users but also in the form of work if servers are batch or processing based
- Use the right instance sizes – do not just throw the nicest looking instance type at a workload. X1 instances all round! 🙂
- Understand and use Reserved Instances, On-Demand Instances and Spot instances – they all have a potential place in your infrastructure
AWS provides you with a significant tool set to implement this strategy and I will outline, using SDL Web as the example, how you can implement these tools to approach building low cost and agile infrastructures.
Putting it into practice?
I have blogged many times on performance of publishing and why with the right setup you can achieve a high-throughput of items published from SDL Web (formerly SDL Tridion). In a previous life with a previous approach to infrastructure, I had helped a customer reach a peak of 850 thousand items publishing in a day. I suspected we could have gone higher but this was the natural load and we never got to give the production infrastructure a full stress test. The implemented infrastructure relied very heavily of physical servers and lots of them to achieve such a high throughput. But this is not the pattern we need to follow, so how do we do this?
What we want to achieve is the following flow of steps:
- We have a minimal infrastructure that serves our basic need
- We detect demand and scale up to meet that demand
- We scale down when the demand has subsided
With this flow, we only use the resources we actually need. For SDL Web, publishing is a fluctuating task and most organizations follow a pattern like:
- They do not typically publish content at night
- They publish several hundred (or thousand) items over a day
- They publish at peak times of just before lunch and just before the end of the day
- They have occasional significantly high peaks in load for site roll outs or large content changes
Publishing in SDL Web, is a more or less stateless process meaning that the queue and the data is outside the process itself, however, during rendering of a publishing job state is held on disk and memory. Whilst it is normal to hold some state in memory or disk, a rendering job could be a significant batch job executed by one server and this poses a complication to scaling down which we need to address.
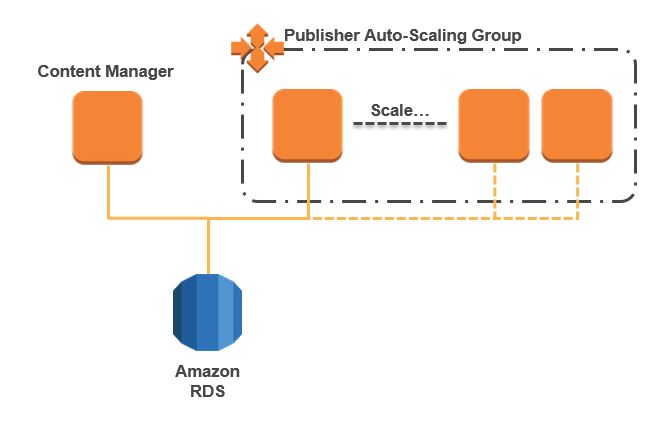
Our high-level architecture is shown in figure 1, and consists of a database, AWS RDS, a Content Manager and a Publisher in an auto-scaling group which will have the ability to scale up and down with demand. Because this is a test architecture focusing on publishing, the Content Manager is not scaled or is redundant. In a production scenario you would probably choose to place the Content Manager behind a load balancer and in its own auto-scaling group. I have also chosen to ignore some additional complications of elements such as Workflow Agents and Search Indexing.
To get the Publishers to scale horizontally, we need to understand what the demand is at a given point in time and scale accordingly. More often than not CPU Utilization is a good metric that shows demand; CPU Utilization is high, therefore you add more capacity to reduce overall utilization. However, Publishers do not work like this, they typically run at a high utilization regardless of demand and therefore this is not a good measure. Demand comes in the form of the queue of items that are waiting so we need to establish if we have 100 or 100,000 items in the queue. To do this I use a Lambda function to query SDL Web and provide a Custom CloudWatch Metric showing the Queue length. This metric will simply give us a number and I chose to get this directly from the database. You could query the RESTFUL API of SDL Web but this is both a little more complex and, in my opinion probably a slower approach; a quick database query will provide what we need for the metric.
The Lambda function is written in .NET Core to be able to leverage the native SQL Server Database drivers. We first define the method (note: the code show in this post is not production worthy code and requires more work to make it so):
public async Task FunctionHandler(ILambdaContext context)
{
Then get the count of the database (ideally you do not hardcode the connection string but I am lazy):
Int32 count = 0;
using (var connection = new SqlConnection("user id=TCMDBUSER;password=12345;server=dbinstance.something.us-east-1.rds.amazonaws.com,1433;database=tridion_cm;connection timeout=45"))
{
connection.Open();
SqlCommand comm = new SqlCommand("SELECT COUNT(*) FROM QUEUE_MESSAGES", connection);
count = (Int32)comm.ExecuteScalar();
}
Now we have the count which we will pass to the metric:
var dimension = new Dimension
{
Name = "Publishing",
Value = "Queue"
};
var metric1 = new MetricDatum
{
Dimensions = new List() { dimension },
MetricName = "Waiting for Publish",
Timestamp = DateTime.Now,
Unit = StandardUnit.Count,
Value = (double)count
};
var request = new PutMetricDataRequest
{
MetricData = new List() { metric1 },
Namespace = "SDL Web"
};
IAmazonCloudWatch client = new AmazonCloudWatchClient();
var response = await client.PutMetricDataAsync(request);
And then close off:
return response.HttpStatusCode.ToString(); }
This will give us a metric which we can then find back in CloudWatch metrics under “SDL Web” and then “Publishing/Queue/Waiting for Publish”. We are then going to set a CloudWatch Alarm to alarm when load is over 100 items in the queue for a sustained period of 5 minutes.
For my auto-scaling group, a Launch Configuration specifies the instance that will be launch when the alarm goes off. The Launch Configuration specifies things like the AMI of my publishing server, security groups to allow it to talk to the database and its role which allows it to talk to other AWS services such as SSM which we will get back to later in this blog post. When the alarm fires, an auto-scaling group policy will take decisions about what to do and is defined as follows:
When the alarm is in breach for a sustained period of 5 minutes the scaling policy will:
- set the auto-scaling group to 2 instances if the queue is between 100 and 1000 content items
- set the auto-scaling group to 3 instances if the queue is between 1000 and 2500 content items
- set the auto-scaling group to 5 instances if the queue is greater than 2500 content items
As demand drops, the auto-scaling group will be set to lower amounts and will eventually return to 1 instance running (the minimum in our auto-scaling group).
So now, we have our Lambda generating our metric and an alarm triggering the auto-scaling group which will then add more instances based upon how high demand is (figure 2).
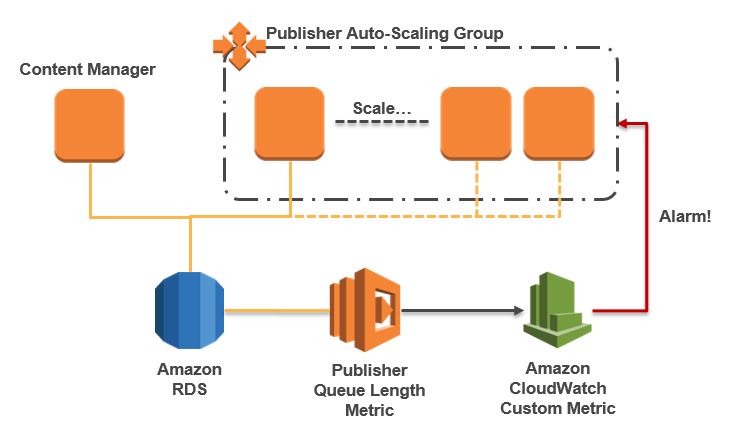
As content editors publish items they will be a small delay, 5 minutes, and then new publishers will be added to publish the content items in the queue. This is just an example on how you could do this. The way the alarm reacts and how quickly up or down you scale is all configurable. Earlier in this post I also mentioned that you typically see higher loads at certain times of the day. As such, we could just add a new publisher at 4 PM to handle the increased load proactively rather that reactively. The choice is yours on how you address this.
When the auto-scaling group removes a publisher we need to be sure that it is done in a nice way. Earlier I mentioned that the publisher is stateless but if it is rendering a content item that will be in memory and on disk. In a recent release of SDL Web, SDL added a graceful shutdown of the publisher, meaning, it will finish what it is doing before it shuts down. When an instance in an auto-scaling group is terminated, processes do not get the chance to cleanly shut down, so we need to use a lifecycle hook to pause termination. Once set, the flow of termination for a publisher is as follows:
- Lifecycle hook on termination pauses termination and waits
- A CloudWatch Event is written to say the hook for our auto-scaling group is waiting
- A CloudWatch rule traps the event and fires a Lambda function in response
- The Lambda function uses AWS Systems Manager (SSM) to stop the publisher and issue a resume on the termination
Each of our publishers is a Managed Instance which means that we can manage its configuration while it is running without needing to log on to the instance. Managing an instance can be a manual process or you can do that from a Lambda function. In this case, we are doing to run the local PowerShell command to stop a service, the publisher. The code, written in Python, is as follows:
Define the handler and the libraries we will use:
def lambda_handler(event, context):
ssmClient = boto3.client('ssm')
s3Client = boto3.client('s3')
asgClient = boto3.client('autoscaling')
set the details of what instance is in termination
message = event['detail'] instanceId = str(message[EC2_KEY]) lifeCycleHook = "SDLWebPubShutdown" autoScalingGroup = "SDLWebPublisherASG"
Send the shutdown command to the instance in the form of a powershell command and wait until it has completed
ssmCommand = ssmClient.send_command(
InstanceIds = [ instanceId ],
DocumentName = 'AWS-RunPowerShellScript',
TimeoutSeconds = 240, Comment = 'Stop Publisher',
Parameters = { 'commands': ["Stop-Service TcmPublisher"] }
)
#poll SSM until EC2 Run Command completes
status = 'Pending'
while status == 'Pending' or status == 'InProgress':
time.sleep(3)
status = (ssmClient.list_commands(CommandId=ssmCommand['Command']['CommandId']))['Commands'][0]['Status']
if(status != 'Success'):
print "Command failed with status " + status
End the waiting termination hook and function
response = asgClient.complete_lifecycle_action( LifecycleHookName=lifeCycleHook, AutoScalingGroupName=autoScalingGroup, LifecycleActionResult='ABANDON', InstanceId=instanceId ) return None
Once we resume the termination, the instance is terminated and the auto-scaling group has been downsized.
Summary
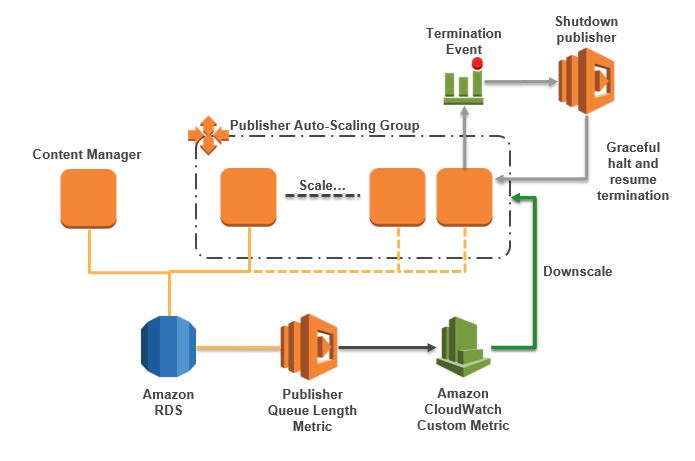
As we can see in figure 3, we have a complete auto-scaling process which will:
- Measure the length of the publishing queue thus recording the current demand
- Use these measurements to scale the publishers horizontally to meet demand
- Gracefully scale back the publishers when demand subsides
In addition we received the following benefits:
- Because we create a metric, we can actively monitor the length of the queue on operational dashboards together with other metrics like CPU Utilization, Network and Memory (operational insights)
- We can easily provision new publisher instances and recycle bad instances quickly (improved agility)
- Reduction in the need for manual intervention (simplification)
We improve the experience of the content editors in the use of the product
This is awesome Julian. Really smart stuff.
Think you could do something similar with the new Deployer Worker?
+1 I agree with Rob. Really useful. Thanks Julian!
Very nice post! How do you handle the licenses on the auto scaling publisher servers? Do you just have enough spare licenses to reach the peak volume of publishing servers?
To get around the license constraints you will need two things 1) a host unlocked license – discuss with SDL and 2) limit your autoscaling group. I had a 4 CPU license with a max scaling range of 5 instances which means I would need to have 20 CPU licenses to scale up completely. I could have few or more should I think I need to publish at different scales, but I can always limit it to my license capacity
really a helpful and nice stuff to use!
This is very good Julian,same things can we do for content management server if loggedin user is more than certain limit then scale one more instance as some times we get slow response while opening content management items.
Nice concept! There’s room for improvement in the implementation, though. 🙂
You say “ideally you do not hardcode the connection string but I am lazy”. I would say “ideally you do not connect to the CM database directly; SDL does not support direct DB connections”. Note that you can get the count of items in the publish queue through the Core Service API and through the Get-TcmQueueInfo PowerShell cmdlet. Would it be easy to use one of those instead of a direct database query?
Also note that SELECT COUNT(*) FROM QUEUE_MESSAGES will give you the number of messages in *all* queues… try running Sync-TcmSearchIndex and see how many publisher instances that will give you 😉
@ Rick, definitely room for improvement to make the solution more sensitive to the different types of setups that are possible. To go DB or Web Service route to get the statistics Both are perfectly possible of course, I just have a preference for the DB route as it involves fewer steps to make it work. Yes, not directly supported to talk directly to the DB but a read from the DB should not be impactful to the DB (never do a write, of course)
@AJAYA, yes you could do the same for the CM. CPU utilization as well as user load may both make sense to use as metrics for scaling up. Some playing around would determine what might make the most sense.
Excellent post! This is not restricted to SDL Web but really provides a good insight on AWS auto-scaling and graceful shutdown.
Thanks
Excellent Post.
Did anyone of you see any deadlock issues in backend SDL CMS database with this approach as CMS DB is only one.
Thanks
You should not see any deadlock issues given the the CMS is designed to scale out to large numbers of publishers and content management servers. Its is a supported deployment model, so any issues you do encounter should be resolved by the support team from SDL.